
Hardly a day goes by these days without a media mention of Artificial Intelligence and / or Machine learning in the space of banking or consumer credit. Depending on the author of the article you are reading, the technology seems either to be the panacea for global financial inclusion or seemingly on its way to become our planetary (financial?) overlord. So, what is the real status of use of these new technology tools on consumer credit and what can we expect happening in the space in the near to medium term. What is the hype and the reality and what is actually actionable in the space now?
The consumer industry context
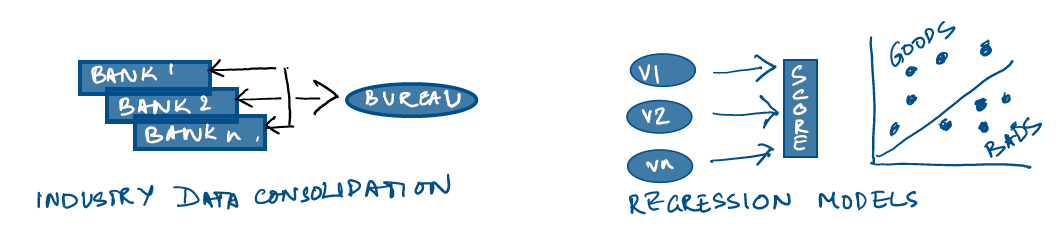
A good place to start answering these questions will be to talk of the state of consumer credit globally and the mechanics of the industry. Understanding and managing consumer risk is the core differentiator for the industry and historically has been a focus problem for the businesses to solve. The way the businesses solved it was by working on the broad principle of past consumer behaviour predicting the future and working on risk thresholds that they wanted to keep within pricing bands. This led banks and regulators to create shared data resources which tracked consumer behaviour. These shared data repositories or ‘credit bureaus’ collated consumer credit information. With this information and information available with the banks themselves, quantitative credit scores could be built which would predict ‘risk’. The scores typically used a variety of variables that significantly differentiated consumer risk. The scores were developed using regression models which have become the de facto standard in the industry.
Changes in the consumer credit industry over the last decade
Data growth and cheaper computing have contributed to very significant changes in the consumer industry over the last decade plus. Additionally, there has, in the period, been a significant regulatory push towards financial inclusion. These shifts in combination have been the fertile ground for AI to work on. To put some of these elements in context within the APac region for instance, of the population base of 4.2bn, about 1.2bn are credit included, which should expose the extent of the financial inclusion agenda. However, telecom growth, ecommerce and payment wallets have together created significant data assets on about 3.5bn people. In parallel, Moore’s law has brought down costs of data storage and computing exponentially over the last decade. All of this gives the AI toolkit the right set of circumstances to work on.

How does AI help consumer credit?
The promise of AI is to be able to apply computing power to discover complex and subtle relationships between variables, which can then be used to build models to segregate good credit from bad credit. AI tools can further help create a virtuous cycle of improving these models in the spirit of ‘machine learning’ with additional incoming data. The difference between AI models and regular regression equations is the level of complexity that the AI models can bring into interpreting consumer data. Where a typical regression equation would use perhaps 8-10 input variables in building an equation to segregate good credit from bad credit, AI algorithms would tend to use a much richer variable set. They would also be able to continually look at these variables and find developing relationships that could model human thinking in using additional data for decision making.
The way then machine learning is being applied to consumer credit is let a human brain modelled ‘neural network’ look at vast amounts of data and train it with (typically) known outcomes. The algorithm works on the data and iterates into a model that provides an optimal line of segregation between good and bad credit performance. This initial model is then used on new consumer application data to predict if the customer is good or bad. The advantage of the learning model is that it can keep a feedback loop alive and take on additional data coming in as the performance of this new consumer plays into the good or the bad bucket. The learning algorithm then incorporates the incremental learning into the model not unlike a human brain creating a virtuous cycle of learning.
All of this sounds great so what, if any, is the problem in the approach? Is this indeed the ‘better mousetrap’? The answer, as ever, is that while the theory of what we have outlined above works very well, there are still a few issues that needs to be resolved as we are moving into the practical usage of AI in consumer credit decisioning.
Explainability – explain better
The current consumer credit model that has been build by the banking system over the ages is a reasonably transparent system that the consumer has been educated on over decades, and the regulators are used to managing systemic risks around. Consumers in this model typically understand the kind of behaviours that impact their credit standing and have the right to ask for information that the banking system holds about them. Regulators similarly have a way to understand the existing models and calculate systemic risks to manage them.
AI models upset this model by making their decisions a ‘black box’, where it is difficult to understand the variables as well as the interactions between them that is leading to the credit decision. The output from the model is hence not ‘explainable’, which is a key issue to resolve in using AI in consumer credit decisioning. Fortunately, this is not a problem without a solution. Various approaches can be used to make these models explainable. While this is a complex field with multiple approaches, suffice to say that developing the ‘explainability’ for the models is fast becoming a key area of parallel research in AI. Practically speaking, it will be necessary to have the process of explaining the model as a key part of the AI model development exercise. However, there may be some areas of usage which may be less sensitive to explainability, which we will talk about shortly.
Bias
Consumer credit models have evolved to remove variables that intrinsically carry bias. This means that credit models currently don’t use variables like gender, ethnicity etc that have the tendency to perpetuate systemic biases. Human beings understand these variables intuitively and have had the time to evolve their understanding of this bias.
For example, given that there is a history in gender pay inequality, if we use gender as a variable in determining credit, all we are doing is help perpetuate this inequality. So we exclude these variables typically when we develop regression models. Machine learning has no such ‘understanding’ of history. It uses all variables that it sees as differentiating credit. In addition, given the point of the ‘black box’ we indicated earlier, it is difficult to see this bias till we feel the consequences of the model. Developing methods to supress these variables that could introduce bias is hence important in the process of evolving AI in credit decisioning. Again, there are ways to solve this. A simple way would be to introduce pre-processes that ensure that variables that are seen supporting bias can be supressed. Additionally, there may be a need to introduce further checks at the time of graduating models to actual usage.
Areas of usage
Another way of thinking about the use of AI in the space of consumer credit, would be to clearly establish clarity on the areas to apply these models with a clear understanding of the strengths and weakness of the methodology. For instance, some of the issues of explainability may not have a significant impact if the area of usage in fraud detection. Fraud detection as an area in banking typically has an exception management process. Learning algorithms in this area ensure that we are making use of the large flow of data that we typically see here. Consumers are also likely to be more understanding of the systemic benefit of this approach as they will eventually gain from the greater fraud detection accuracy. Other areas of usage that could be more acceptable to consumers, would be in predicting consumer life cycle events to better direct marketing campaigns. Again, privacy concerns being taken care of, the consumers are likely to be more understanding of the use of AI in this area.
In conclusion, while there may be other issues to be looked at in the use of AI in consumer decisioning, the ones in mention above are the key areas to resolve at this point. Given the undeniable benefit that the use of AI can bring to the space by harnessing consumer data to solve for financial inclusion, the efforts in all of these are well worth investing in. The question hence is less of whether AI is usable in consumer credit and more of how soon we will be able to productively harness these capabilities to address one of the biggest problems of our era, financial inclusion.
Mohan Jayaraman
Managing Director, Innovation & Strategy, Experian Asia Pacific